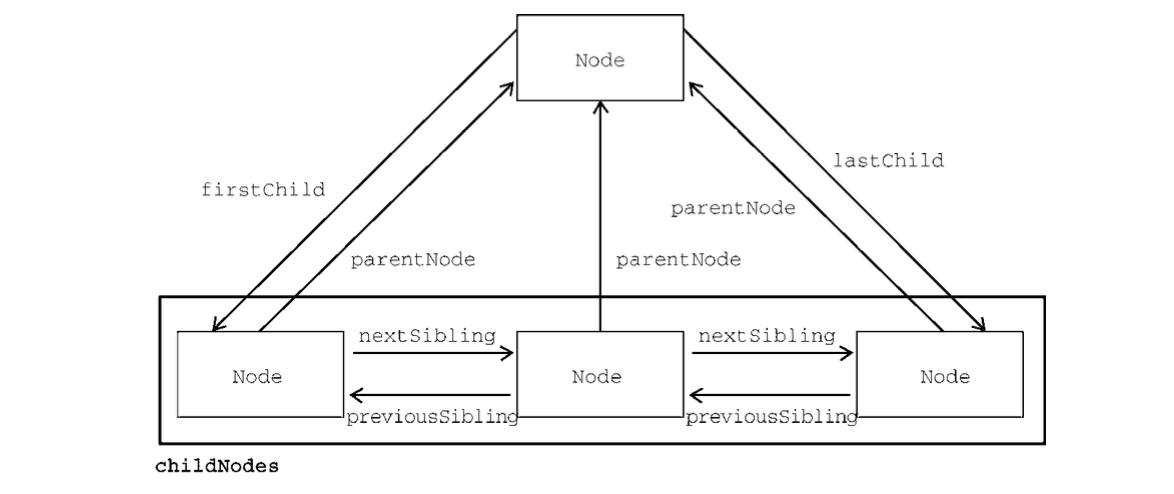
Dom
Node类型
操纵节点
appendChild()方法返回新添加的节点,如下所示:
如果想把节点放到 childNodes 中的特定位置而不是末尾,则可以使用 insertBefore()方法。 这个方法接收两个参数:要插入的节点和参照节点。调用这个方法后,要插入的节点会变成参照节点的 前一个同胞节点,并被返回。如果参照节点是 null,则 insertBefore()与 appendChild()效果相 同,如下面的例子所示:
appendChild()和 insertBefore()在插入节点时不会删除任何已有节点。相对地, replaceChild()方法接收两个参数:要插入的节点和要替换的节点。要替换的节点会被返回并从文档 树中完全移除,要插入的节点会取而代之。下面看一个例子:
要移除节点而不是替换节点,可以使用 removeChild()方法。这个方法接收一个参数,即要移除 的节点。被移除的节点会被返回,如下面的例子所示:
cloneNode() 方法用于克隆一个节点,并返回克隆后的节点。该方法可以接受一个布尔值参数,用于指定克隆节点时是否深度克隆其所有子节点。当参数为 true 时,表示深度克隆,即同时克隆该节点的所有子节点;当参数为 false 时,表示浅克隆,即只克隆该节点本身,不包括其所有子节点。下面是 cloneNode(true) 和 cloneNode(false) 的区别:
cloneNode(true):深度克隆节点及其所有子节点。 cloneNode(false):浅克隆节点本身,不包括其所有子节点。
注意 cloneNode()方法不会复制添加到 DOM 节点的 JavaScript 属性,比如事件处理程 序。这个方法只复制 HTML 属性,以及可选地复制子节点。除此之外则一概不会复制。 IE 在很长时间内会复制事件处理程序,这是一个 bug,所以推荐在复制前先删除事件处 理程序。
Document类型
URL 跟域名是相关的。比如,如果 document.URL 是 http://www.wrox.com/WileyCDA/,则 document.domain 就是 <www.wrox.com。> 如果 URL 包含子域名如 p2p.wrox.com,则可以将 domain 设置为"wrox.com"(URL 包含“www” 1 时也一样,比如 <www.wrox.com)。不能给这个属性设置> URL 中不包含的值,比如:
当页面中包含来自某个不同子域的窗格(<frame>)或内嵌窗格(<iframe>)时,设置 document.domain 是有用的。因为跨源通信存在安全隐患,所以不同子域的页面间无法通过 JavaScript 通信。此时,在每个页面上把 document.domain 设置为相同的值,这些页面就可以访问对方的 JavaScript 对象了。比如,一个加载自 <www.wrox.com> 的页面中包含一个内嵌窗格,其中的页面加载自 p2p.wrox.com。这两个页面的 document.domain 包含不同的字符串,内部和外部页面相互之间不能 访问对方的 JavaScript 对象。如果每个页面都把 document.domain 设置为 wrox.com,那这两个页面 之间就可以通信了。 5 浏览器对 domain 属性还有一个限制,即这个属性一旦放松就不能再收紧。比如,把 document.domain 设置为"wrox.com"之后,就不能再将其设置回"p2p.wrox.com",后者会导致错 误,比如:
Element类型
HTML 元素:
这个元素中的所有属性都可以使用下列 JavaScript 代码(对象属性)读取:
而且,可以使用下列代码修改元素的属性:
getAttribute()方法也能取得不是 HTML 语言正式属性的自定义属性的值。比如下面的元素:
注意,属性名不区分大小写,因此"ID"和"id"被认为是同一个属性。另外,根据 HTML5 规范的 要求,自定义属性名应该前缀 data-以方便验证。 因为 id 和 align 在 HTML 中是<div>元素公认的属性,所以 DOM 对象上也会有这两个属性。但 my_special_attribute 是自定义属性,因此不会成为 DOM 对象的属性。
考虑到以上差异,开发者在进行 DOM 编程时通常会放弃使用 getAttribute()而只使用对象属性。 getAttribute()主要用于取得自定义属性的值。
设置属性
与 getAttribute()配套的方法是 setAttribute(),这个方法接收两个参数:要设置的属性名 和属性的值。如果属性已经存在,则 setAttribute()会以指定的值替换原来的值;如果属性不存在, 11 则 setAttribute()会以指定的值创建该属性。下面看一个例子:
setAttribute()适用于 HTML 属性,也适用于自定义属性。另外,使用 setAttribute()方法 设置的属性名会规范为小写形式,因此"ID"会变成"id"。 因为元素属性也是 DOM 对象属性,所以直接给 DOM 对象的属性赋值也可以设置元素属性的值, 如下所示:
注意,在 DOM 对象上添加自定义属性,如下面的例子所示,不会自动让它变成元素的属性:
最后一个方法 removeAttribute()用于从元素中删除属性。这样不单单是清除属性的值,而是会 把整个属性完全从元素中去掉,如下所示:
这个方法用得并不多,但在序列化 DOM 元素时可以通过它控制要包含的属性。
DocumentFragment类型
假设想给这个<ul>元素添加 3 个列表项。如果分 3 次给这个元素添加列表项,浏览器就要重新渲染 3 次页面,以反映新添加的内容。为避免多次渲染,下面的代码示例使用文档片段创建了所有列表项, 然后一次性将它们添加到了<ul>元素:
DOM 编程
动态脚本
动态样式
另一种定义样式的方式是使用<script>元素包含嵌入的 CSS 规则,例如:
逻辑上,下列 DOM 代码会有同样的效果:
MutationObserver接口
MutationObserver 接口可以在 DOM 被修改时异步执行回调。使 用 MutationObserver 可以观察整个文档、DOM 树的一部分,或某个元素。此外还可以观察元素属性、子节点、文本,或者前三者任意组合的变化。
MutationObserver 的实例要通过调用 MutationObserver 构造函数并传入一个回调函数来创建:
observe()方法
新创建的 MutationObserver 实例不会关联 DOM 的任何部分。要把这个 observer 与 DOM 关 联起来,需要使用 observe()方法。这个方法接收两个必需的参数:要观察其变化的 DOM 节点,以及 一个 MutationObserverInit 对象。
MutationObserverInit 对象用于控制观察哪些方面的变化,是一个键/值对形式配置选项的字典。 例如,下面的代码会创建一个观察者(observer)并配置它观察<body>元素上的属性变化:
执行以上代码后,<body>元素上任何属性发生变化都会被这个 MutationObserver 实例发现,然 后就会异步执行注册的回调函数。<body>元素后代的修改或其他非属性修改都不会触发回调进入任务 队列。可以通过以下代码来验证:
注意,回调中的 console.log()是后执行的。这表明回调并非与实际的 DOM 变化同步执行。
回调与 MutationRecord
每个回调都会收到一个 MutationRecord 实例的数组。MutationRecord 实例包含的信息包括发 生了什么变化,以及 DOM 的哪一部分受到了影响。因为回调执行之前可能同时发生多个满足观察条件 的事件,所以每次执行回调都会传入一个包含按顺序入队的 MutationRecord 实例的数组。 下面展示了反映一个属性变化的 MutationRecord 实例的数组:
下面是一次涉及命名空间的类似变化:
连续修改会生成多个 MutationRecord 实例,下次回调执行时就会收到包含所有这些实例的数组, 顺序为变化事件发生的顺序:
传给回调函数的第二个参数是观察变化的 MutationObserver 的实例,演示如下:
disconnect()方法 默认情况下,只要被观察的元素不被垃圾回收,MutationObserver 的回调就会响应 DOM 变化事 件,从而被执行。要提前终止执行回调,可以调用 disconnect()方法。下面的例子演示了同步调用 disconnect()之后,不仅会停止此后变化事件的回调,也会抛弃已经加入任务队列要异步执行的回调:
要想让已经加入任务队列的回调执行,可以使用 setTimeout()让已经入列的回调执行完毕再调用 disconnect():
复用 MutationObserver
多次调用 observe()方法,可以复用一个 MutationObserver 对象观察多个不同的目标节点。此 时,MutationRecord 的 target 属性可以标识发生变化事件的目标节点。下面的示例演示了这个过程:
重用 MutationObserver
调用 disconnect()并不会结束 MutationObserver 的生命。还可以重新使用这个观察者,再将 它关联到新的目标节点。下面的示例在两个连续的异步块中先断开然后又恢复了观察者与<body>元素 的关联:
takeRecords()方法
调用 MutationObserver 实例的 takeRecords()方法可以清空记录队列,取出并返回其中的所 4 有 MutationRecord 实例。看这个例子:
这在希望断开与观察目标的联系,但又希望处理由于调用 disconnect()而被抛弃的记录队列中的 MutationRecord 实例时比较有用。
MutationObserverInit与观察范围
subtree
布尔值,表示除了目标节点,是否观察目标节点的子树(后代) 如果是 false,则只观察目标节点的变化;如果是 true,则观察目标节点及其整个子树 默认为 false
attributes
布尔值,表示是否观察目标节点的属性变化 默认为 false
attributeFilter
字符串数组,表示要观察哪些属性的变化 把这个值设置为 true 也会将 attributes 的值转换为 true 默认为观察所有属性
attributeOldValue
布尔值,表示 MutationRecord 是否记录变化之前的属性值 把这个值设置为 true 也会将 attributes 的值转换为 true 默认为 false
characterData
布尔值,表示修改字符数据是否触发变化事件 默认为 false
characterDataOldValue
布尔值,表示 MutationRecord 是否记录变化之前的字符数据 把这个值设置为 true 也会将 characterData 的值转换为 true 默认为 false
childList
布尔值,表示修改目标节点的子节点是否触发变化事件 默认为 false
注意 在调用observe()时,MutationObserverInit对象中的attribute、characterData 和childList属性必须至少有一项为true(无论是直接设置这几个属性,还是通过设置 attributeOldValue 等属性间接导致它们的值转换为 true)。否则会抛出错误,因为没 有任何变化事件可能触发回调。
观察属性
MutationObserver 可以观察节点属性的添加、移除和修改。要为属性变化注册回调,需要在 MutationObserverInit 对象中将 attributes 属性设置为 true,如下所示:
DOM扩展
matches()
matches()方法(在规范草案中称为 matchesSelector())接收一个 CSS 选择符参数,如果元素 匹配则该选择符返回 true,否则返回 false。例如:
使用这个方法可以方便地检测某个元素会不会被 querySelector()或 querySelectorAll()方 法返回。 所有主流浏览器都支持 matches()。Edge、Chrome、Firefox、Safari 和 Opera 完全支持,IE9~11 及一些移动浏览器支持带前缀的方法。
getElementsByClassName()
etElementsByClassName()方法接收一个参数,即包含一个或多个类名的字符串,返回类名中 包含相应类的元素的 NodeList。如果提供了多个类名,则顺序无关紧要。下面是几个示例:
classList 属性
HTML5 通过给所有元素增加 classList 属性为这些操作提供了更简单也更安全的实现方式。 classList 是一个新的集合类型 DOMTokenList 的实例。与其他 DOM 集合类型一样,DOMTokenList 也有 length 属性表示自己包含多少项,也可以通过 item()或中括号取得个别的元素。此外, DOMTokenList 还增加了以下方法。 24
add(value),向类名列表中添加指定的字符串值 value。如果这个值已经存在,则什么也不做。 contains(value),返回布尔值,表示给定的 value 是否存在。
remove(value),从类名列表中删除指定的字符串值 value。
toggle(value),如果类名列表中已经存在指定的 value,则删除;如果不存在,则添加。 这样以来,前面的例子中那么多行代码就可以简化成下面的一行:
这行代码可以在不影响其他类名的情况下完成删除。其他方法同样极大地简化了操作类名的复杂 性,如下面的例子所示:
焦点管理
HTML5 增加了辅助 DOM 焦点管理的功能。首先是 document.activeElement,始终包含当前拥 有焦点的 DOM 元素。页面加载时,可以通过用户输入(按 Tab 键或代码中使用 focus()方法)让某个 元素自动获得焦点。例如:
默认情况下,document.activeElement 在页面刚加载完之后会设置为 document.body。而在 页面完全加载之前,document.activeElement 的值为 null。 其次是 document.hasFocus()方法,该方法返回布尔值,表示文档是否拥有焦点:
确定文档是否获得了焦点,就可以帮助确定用户是否在操作页面。 第一个方法可以用来查询文档,确定哪个元素拥有焦点,第二个方法可以查询文档是否获得了焦点, 而这对于保证 Web 应用程序的无障碍使用是非常重要的。无障碍 Web 应用程序的一个重要方面就是焦 点管理,而能够确定哪个元素当前拥有焦点(相比于之前的猜测)是一个很大的进步。
HTMLDocument扩展
readyState 属性
document.readyState 属性有两个可能的值:
loading,表示文档正在加载;
complete,表示文档加载完成。
实际开发中,最好是把 document.readState 当成一个指示器,以判断文档是否加载完毕。在这 个属性得到广泛支持以前,通常要依赖 onload 事件处理程序设置一个标记,表示文档加载完了。这个 属性的基本用法如下:
自定义数据属性
自定义数据属性非常适合需要给元素附加某些数据的场景,比如链接追踪和在聚合应用程序中标识 页面的不同部分。另外,单页应用程序框架也非常多地使用了自定义数据属性。
insertAdjacentHTML()与 insertAdjacentText()
关于插入标签的最后两个新增方法是 insertAdjacentHTML()和 insertAdjacentText()。这两 个方法最早源自 IE,它们都接收两个参数:要插入标记的位置和要插入的 HTML 或文本。第一个参数 必须是下列值中的一个:
"beforebegin",插入当前元素前面,作为前一个同胞节点;
"afterbegin",插入当前元素内部,作为新的子节点或放在第一个子节点前面;
"beforeend",插入当前元素内部,作为新的子节点或放在最后一个子节点后面;
"afterend",插入当前元素后面,作为下一个同胞节点。 注意这几个值是不区分大小写的。第二个参数会作为 HTML 字符串解析(与 innerHTML 和 outerHTML 相同)或者作为纯文本解析(与 innerText 和 outerText 相同)。如果是 HTML,则会 在解析出错时抛出错误。下面展示了基本用法1:
scrollIntoView()
DOM 规范中没有涉及的一个问题是如何滚动页面中的某个区域。为填充这方面的缺失,不同浏览 器实现了不同的控制滚动的方式。在所有这些专有方法中,HTML5 选择了标准化 scrollIntoView()。 scrollIntoView()方法存在于所有 HTML 元素上,可以滚动浏览器窗口或容器元素以便包含元 素进入视口。这个方法的参数如下:
alignToTop 是一个布尔值。
true:窗口滚动后元素的顶部与视口顶部对齐。 false:窗口滚动后元素的底部与视口底部对齐。
scrollIntoViewOptions 是一个选项对象。
behavior:定义过渡动画,可取的值为"smooth"和"auto",默认为"auto"。
block:定义垂直方向的对齐,可取的值为"start"、"center"、"end"和"nearest",默 认为 "start"。
inline:定义水平方向的对齐,可取的值为"start"、"center"、"end"和"nearest",默 认为 "nearest"。
不传参数等同于 alignToTop 为 true。 来看几个例子:
这个方法可以用来在页面上发生某个事件时引起用户关注。把焦点设置到一个元素上也会导致浏览 器将元素滚动到可见位置。
遍历
DOM2 Traversal and Range 模块定义了两个类型用于辅助顺序遍历 DOM 结构。这两个类型—— NodeIterator 和 TreeWalker——从某个起点开始执行对 DOM 结构的深度优先遍历。 如前所述,DOM 遍历是对 DOM 结构的深度优先遍历,至少允许朝两个方向移动(取决于类型)。 遍历以给定节点为根,不能在 DOM 中向上超越这个根节点。来看下面的 HTML:
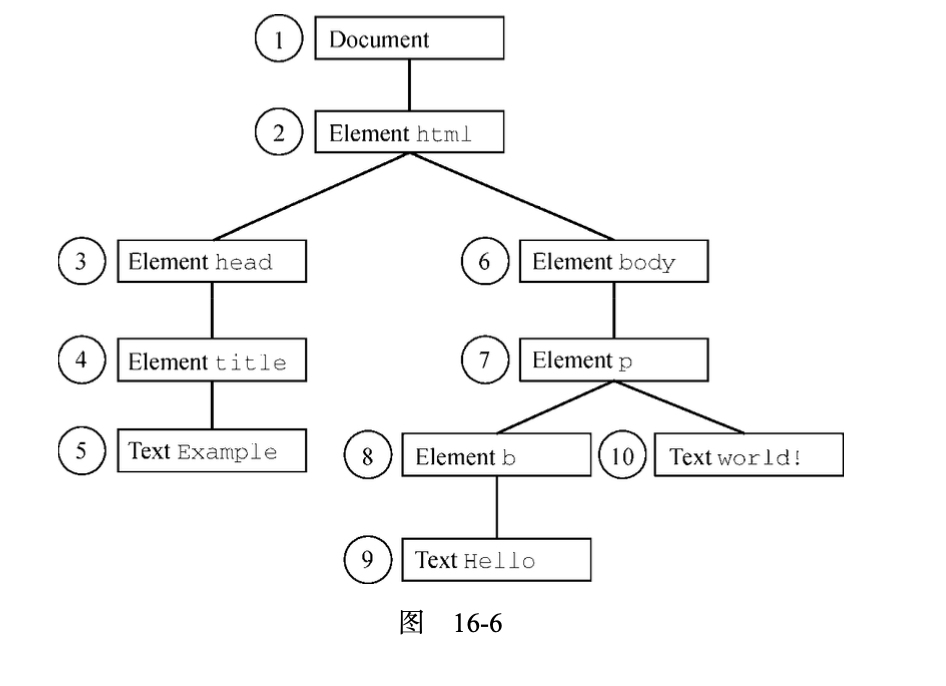
其中的任何节点都可以成为遍历的根节点。比如,假设以<body>元素作为遍历的根节点,那么接 下来是<p>元素、<b>元素和两个文本节点(都是<body>元素的后代)。但这个遍历不会到达<html>元 素、<head>元素,或者其他不属于<body>元素子树的元素。而以 document 为根节点的遍历,则可以 访问到文档中的所有节点。图 16-6 展示了以 document 为根节点的深度优先遍历。
NodeIterator
NodeIterator 类型是两个类型中比较简单的,可以通过 document.createNodeIterator()方 法创建其实例。这个方法接收以下 4 个参数。
root,作为遍历根节点的节点。
whatToShow,数值代码,表示应该访问哪些节点。
filter,NodeFilter 对象或函数,表示是否接收或跳过特定节点。
entityReferenceExpansion,布尔值,表示是否扩展实体引用。这个参数在 HTML 文档中没 有效果,因为实体引用永远不扩展
假设想要遍历
元素内部的所有元素,那么可以使用如下代码:
这个例子中第一次调用 nextNode()返回
元素。因为 nextNode()在遍历到达 DOM 子树末 尾时返回 null,所以这里通过 while 循环检测每次调用 nextNode()的返回值是不是 null。以上代 码执行后会输出以下标签名: DIV P B UL LI LI LI 如果只想遍历<li>元素,可以传入一个过滤器,比如:
// 输出标签名 在这个例子中,遍历只会输出<li>元素的标签。 nextNode()和 previousNode()方法共同维护 NodeIterator 对 DOM 结构的内部指针,因此修 改 DOM 结构也会体现在遍历中。
TreeWalker
TreeWalker 是 NodeIterator 的高级版。除了包含同样的 nextNode()、previousNode()方法, TreeWalker 还添加了如下在 DOM 结构中向不同方向遍历的方法。
parentNode(),遍历到当前节点的父节点。
firstChild(),遍历到当前节点的第一个子节点。
lastChild(),遍历到当前节点的最后一个子节点。
nextSibling(),遍历到当前节点的下一个同胞节点。
previousSibling(),遍历到当前节点的上一个同胞节点。
DOM 范围
DOM2 在 Document 类型上定义了一个 createRange()方法,暴露在 document 对象上。使用这 个方法可以创建一个 DOM 范围对象,如下所示:
简单选择
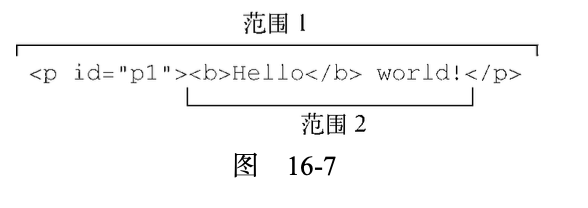
以下 JavaScript 代码可以访问并创建相应的范围:
例子中的这两个范围包含文档的不同部分。range1 包含<p>元素及其所有后代,而 range2 包含 <b>元素、文本节点"Hello"和文本节点" world!",如图 16-7 所示。
Last updated